The result distribution from multiple different runs can be used as confidence intervals. This will establish a connection between the pipeline and the device, which is necessary for the pipeline to run. Because the Inception model has already been pre-trained on thousands of different images, internally it contains the image features needed for image identification. each sample in a batch should have in computing the total loss. Can the professor have 90% confidence that the mean score for the class on the test would be above 70. To check how good are ACCESSIBLE, CONVENIENT, EASY & SECURE ENROLL ONLINE Student Systems NU Quest Online facility for application, admission, and requirements gathering for new students and transferees. In addition, he is an experienced technical writer with over 50 published reports.  import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers Introduction. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. WebAt SAP, we believe we are made stronger by the unique capabilities and qualities that each person brings to our company, and we invest in our employees to inspire confidence and help everyone realize their full potential. This tutorial shows how to classify images of flowers using a tf.keras.Sequential model and load data using tf.keras.utils.image_dataset_from_directory. In last weeks tutorial, we trained an image classification model on a vegetable image dataset in the TensorFlow framework. since the optimizer does not have access to validation metrics. TensorFlow Lite is a set of tools that enables on-device machine learning by helping developers run their models on mobile, embedded, and edge devices. In this example, take the trained Keras Sequential model and use tf.lite.TFLiteConverter.from_keras_model to generate a TensorFlow Lite model: The TensorFlow Lite model you saved in the previous step can contain several function signatures. I didn't vote down, but from what I understand the proposed method would output intervals that capture the model's predicted values, this is not the same as intervals that capture the true values. It only takes a minute to sign up. I got a database of 50 photos, used this video to get me started, and it DID work with Google's Sample Model (I'm using a RPi4B with 8 GB of RAM), then I wanted to create my own model. Run all code examples in your web browser works on Windows, macOS, and Linux (no dev environment configuration required!) What happens if we set the prediction interval and confidence interval around the regression line at ".9999999", Feedforward neural network for sinusoidal prediction. next epoch. 84+ hours of on-demand video
So it say that I think that real response is lie in [20-5, 20+5] but to really understand what does it mean, we need to understand real phenomen and mathematical model.
import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers Introduction. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. WebAt SAP, we believe we are made stronger by the unique capabilities and qualities that each person brings to our company, and we invest in our employees to inspire confidence and help everyone realize their full potential. This tutorial shows how to classify images of flowers using a tf.keras.Sequential model and load data using tf.keras.utils.image_dataset_from_directory. In last weeks tutorial, we trained an image classification model on a vegetable image dataset in the TensorFlow framework. since the optimizer does not have access to validation metrics. TensorFlow Lite is a set of tools that enables on-device machine learning by helping developers run their models on mobile, embedded, and edge devices. In this example, take the trained Keras Sequential model and use tf.lite.TFLiteConverter.from_keras_model to generate a TensorFlow Lite model: The TensorFlow Lite model you saved in the previous step can contain several function signatures. I didn't vote down, but from what I understand the proposed method would output intervals that capture the model's predicted values, this is not the same as intervals that capture the true values. It only takes a minute to sign up. I got a database of 50 photos, used this video to get me started, and it DID work with Google's Sample Model (I'm using a RPi4B with 8 GB of RAM), then I wanted to create my own model. Run all code examples in your web browser works on Windows, macOS, and Linux (no dev environment configuration required!) What happens if we set the prediction interval and confidence interval around the regression line at ".9999999", Feedforward neural network for sinusoidal prediction. next epoch. 84+ hours of on-demand video
So it say that I think that real response is lie in [20-5, 20+5] but to really understand what does it mean, we need to understand real phenomen and mathematical model. 
 These can be included inside your model like other layers, and run on the GPU. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, No, train_op is the tensor for the training. Even assume it's additive "predict_for_mean" + "predict_for_error". In prediction you duplicate the case and expand that into a batch and enable the dropout, then you will obtain multiple outputs for the same input but with different dropped parameters. instance, a regularization loss may only require the activation of a layer (there are threshold, Changing the learning rate of the model when training seems to be plateauing, Doing fine-tuning of the top layers when training seems to be plateauing, Sending email or instant message notifications when training ends or where a certain This is only for classification, how about if it was a regression problem. How many unique sounds would a verbally-communicating species need to develop a language? If the classification result is not None (i.e., the classification was successful), we use the cv2.putText() function to write the class label and confidence score on the image. These Neural Networks can be trained on a CPU but take a lot of time. There was no need ti downvote, just ask for clarification, but oh well. data & labels. The image classification model we trained can classify one of the 15 vegetables (e.g., tomato, brinjal, and bottle gourd). Save and categorize content based on your preferences. We learned the OAK hardware and software stack from the ground level. Should't it be between 0-1? Data augmentation takes the approach of generating additional training data from your existing examples by augmenting them using random transformations that yield believable-looking images. The learning decay schedule could be static (fixed in advance, as a function of the
These can be included inside your model like other layers, and run on the GPU. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, No, train_op is the tensor for the training. Even assume it's additive "predict_for_mean" + "predict_for_error". In prediction you duplicate the case and expand that into a batch and enable the dropout, then you will obtain multiple outputs for the same input but with different dropped parameters. instance, a regularization loss may only require the activation of a layer (there are threshold, Changing the learning rate of the model when training seems to be plateauing, Doing fine-tuning of the top layers when training seems to be plateauing, Sending email or instant message notifications when training ends or where a certain This is only for classification, how about if it was a regression problem. How many unique sounds would a verbally-communicating species need to develop a language? If the classification result is not None (i.e., the classification was successful), we use the cv2.putText() function to write the class label and confidence score on the image. These Neural Networks can be trained on a CPU but take a lot of time. There was no need ti downvote, just ask for clarification, but oh well. data & labels. The image classification model we trained can classify one of the 15 vegetables (e.g., tomato, brinjal, and bottle gourd). Save and categorize content based on your preferences. We learned the OAK hardware and software stack from the ground level. Should't it be between 0-1? Data augmentation takes the approach of generating additional training data from your existing examples by augmenting them using random transformations that yield believable-looking images. The learning decay schedule could be static (fixed in advance, as a function of the
Login NU Information System Lets now dive one step further and use the OAKs color camera to classify the frames, which in our opinion, is where you put your OAK module to real use, catering to a wide variety of applications discussed in the 1st blog post of this series. Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colabs ecosystem right in your web browser! How will Conclave Sledge-Captain interact with Mutate? It also To use the trained model with on-device applications, first convert it to a smaller and more efficient model format called a TensorFlow Lite model. You can imagine any schema to predict signal and error separately.  Let's now take a look at the case where your data comes in the form of a about models that have multiple inputs or outputs? A dynamic learning rate schedule (for instance, decreasing the learning rate when the that counts how many samples were correctly classified as belonging to a given class: The overwhelming majority of losses and metrics can be computed from y_true and Comparison of two sample means in R. 5. This phenomenon is known as overfitting. Does NEC allow a hardwired hood to be converted to plug in? To check how good are your assumptions for the validation data you may want to look at $\frac{y_i-\mu(x_i)}{\sigma(x_i)}$ to see if they roughly follow a $N(0,1)$. All three are working fine for me. Its a sanity check to ensure the conversion from TensorFlow to IR works as expected. All values in a row sum up to 1 (because the final layer of our model uses Softmax activation function). To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Abstract Predicting the function of a protein from its amino acid sequence is a long-standing challenge in bioinformatics. But if you give me a photo of an ostrich and force my hand to decide if it's a cat or a dog I better return a prediction with very low confidence.". 0.
Let's now take a look at the case where your data comes in the form of a about models that have multiple inputs or outputs? A dynamic learning rate schedule (for instance, decreasing the learning rate when the that counts how many samples were correctly classified as belonging to a given class: The overwhelming majority of losses and metrics can be computed from y_true and Comparison of two sample means in R. 5. This phenomenon is known as overfitting. Does NEC allow a hardwired hood to be converted to plug in? To check how good are your assumptions for the validation data you may want to look at $\frac{y_i-\mu(x_i)}{\sigma(x_i)}$ to see if they roughly follow a $N(0,1)$. All three are working fine for me. Its a sanity check to ensure the conversion from TensorFlow to IR works as expected. All values in a row sum up to 1 (because the final layer of our model uses Softmax activation function). To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Abstract Predicting the function of a protein from its amino acid sequence is a long-standing challenge in bioinformatics. But if you give me a photo of an ostrich and force my hand to decide if it's a cat or a dog I better return a prediction with very low confidence.". 0.  Is there a way to get actual float values instead of just 1 and zeroes?\. Using an RC delay circuit on an NPN BJT base. I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Is there a way to get actual float values instead of just 1 and zeroes?\. Using an RC delay circuit on an NPN BJT base. I strongly believe that if you had the right teacher you could master computer vision and deep learning. 
 You can pass a Dataset instance directly to the methods fit(), evaluate(), and
You can pass a Dataset instance directly to the methods fit(), evaluate(), and
This is a batch of 32 images of shape 180x180x3 (the last dimension refers to color channels RGB). On Line 12, we call utils.create_pipeline_camera(), which initializes the depthai pipeline for capturing video frames from the OAK camera and performing image classification. With the configurations and utilities implemented, we can finally get into the code walkthrough of classifying images on OAK-D. We start by importing the necessary packages, including the config and utils modules from pyimagesearch, and the os, numpy, cv2, and depthai modules on Lines 2-7.
AFAIK prediction uncertainty like this is actually an open research problem, especially given that the scores returned by two-tower models are usually unnormalized and not probabilities. The keypoints detected are indexed by a part ID, with a confidence score between 0.0 and 1.0.
Regression networks trained to minimise the mean-squared error learn the conditional mean of the target distribution, so the output of the first network is an estimate of the conditional mean of the targets and the second learns the conditional mean of the squared distance of the targets from the mean, i.e. I and others have been arguing that predictive distributions are much more useful than point predictions, but to be honest, I have not yet seen a lot of work on predictive distributions with neural nets, although I have been keeping my eyes open.
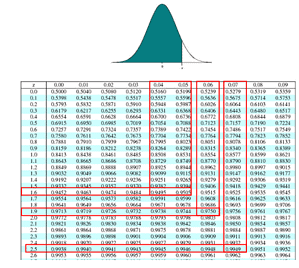
As a deep learning engineer or practitioner, you may be working in a team building a product that requires you to train deep learning models on a specific data modality (e.g., computer vision) on a daily basis. In fact, this is even built-in as the ReduceLROnPlateau callback. Conditions required for a society to develop aquaculture? Its a brilliant idea that saves you money. Register Online Payment A secure encrypted portal to pay fees and tuition online using credit cards or e-wallets. This should only be used at test time. In Keras, model.predict() actually returns you the confidence(s). You can If $e$ is your error rate while classifying some data $S$ of size $n$, a 95% confidence interval for your error rate is given by:  With the frame and neural network data queues defined and the frame postprocessing helper function in place, we start the while loop on Line 45. behavior of the model, in particular the validation loss). The pipeline object returned by the function is assigned to the variable, It would create a pipeline that is ready to process images and perform inference using the, Next, the function extracts the class label by getting the index of the maximum probability and then using it to look up the corresponding label in the. This is hard to do, but popular methods include running MC dropout at prediction time, or ensembling. TensorFlow Lite for mobile and edge devices, TensorFlow Extended for end-to-end ML components, Pre-trained models and datasets built by Google and the community, Ecosystem of tools to help you use TensorFlow, Libraries and extensions built on TensorFlow, Differentiate yourself by demonstrating your ML proficiency, Educational resources to learn the fundamentals of ML with TensorFlow, Resources and tools to integrate Responsible AI practices into your ML workflow, Stay up to date with all things TensorFlow, Discussion platform for the TensorFlow community, User groups, interest groups and mailing lists, Guide for contributing to code and documentation, Tune hyperparameters with the Keras Tuner, Warm start embedding matrix with changing vocabulary, Classify structured data with preprocessing layers. You can further use np.where () as shown below to determine which of the two probabilities (the one over 50%) will be the final class. This confidence score is alright as we're not dealing with model accuracy (which requires the truth value beforehand), and we're dealing with data the model hasn't seen before. The softmax is a problematic way to estimate a confidence of the model`s prediction. There are a few recent papers about this topic. You can look For a quick illustration, see the Wikipedia page under Generalization and Statistics.
With the frame and neural network data queues defined and the frame postprocessing helper function in place, we start the while loop on Line 45. behavior of the model, in particular the validation loss). The pipeline object returned by the function is assigned to the variable, It would create a pipeline that is ready to process images and perform inference using the, Next, the function extracts the class label by getting the index of the maximum probability and then using it to look up the corresponding label in the. This is hard to do, but popular methods include running MC dropout at prediction time, or ensembling. TensorFlow Lite for mobile and edge devices, TensorFlow Extended for end-to-end ML components, Pre-trained models and datasets built by Google and the community, Ecosystem of tools to help you use TensorFlow, Libraries and extensions built on TensorFlow, Differentiate yourself by demonstrating your ML proficiency, Educational resources to learn the fundamentals of ML with TensorFlow, Resources and tools to integrate Responsible AI practices into your ML workflow, Stay up to date with all things TensorFlow, Discussion platform for the TensorFlow community, User groups, interest groups and mailing lists, Guide for contributing to code and documentation, Tune hyperparameters with the Keras Tuner, Warm start embedding matrix with changing vocabulary, Classify structured data with preprocessing layers. You can further use np.where () as shown below to determine which of the two probabilities (the one over 50%) will be the final class. This confidence score is alright as we're not dealing with model accuracy (which requires the truth value beforehand), and we're dealing with data the model hasn't seen before. The softmax is a problematic way to estimate a confidence of the model`s prediction. There are a few recent papers about this topic. You can look For a quick illustration, see the Wikipedia page under Generalization and Statistics.  Do you observe increased relevance of Related Questions with our Machine How do I merge two dictionaries in a single expression in Python? and you've seen how to use the validation_data and validation_split arguments in How much technical information is given to astronauts on a spaceflight? Sequential models, models built with the Functional API, and models written from
Do you observe increased relevance of Related Questions with our Machine How do I merge two dictionaries in a single expression in Python? and you've seen how to use the validation_data and validation_split arguments in How much technical information is given to astronauts on a spaceflight? Sequential models, models built with the Functional API, and models written from
Why exactly is discrimination (between foreigners) by citizenship considered normal? The professor wants the class to be able to score above 70 on the test. can pass the steps_per_epoch argument, which specifies how many training steps the each output, and you can modulate the contribution of each output to the total loss of View all the layers of the network using the Keras Model.summary method: Train the model for 10 epochs with the Keras Model.fit method: Create plots of the loss and accuracy on the training and validation sets: The plots show that training accuracy and validation accuracy are off by large margins, and the model has achieved only around 60% accuracy on the validation set. 0. 0. fit(), when your data is passed as NumPy arrays. If you want to run training only on a specific number of batches from this Dataset, you This This helps expose the model to more aspects of the data and generalize better. There is no way, all ML models is not about phenomen understanding, it's interpolation methods with hope "that it works". Use MathJax to format equations. Start with such questions confidence, robustnes to noise there is no answers. 0. You can call .numpy() on the image_batch and labels_batch tensors to convert them to a numpy.ndarray. This guide covers training, evaluation, and prediction (inference) You can create a custom callback by extending the base class  Finally, on Line 78, the function returns the pipeline object, which has been configured with the classifier model, color camera, image manipulation node, and input/output streams. 0. (the one passed to compile()). Now, lets start with todays tutorial and learn about the deployment on OAK! It's possible to give different weights to different output-specific losses (for The confidence of that prediction is simply the probability of the top item. shape (764,)) and a single output (a prediction tensor of shape (10,)). In particular, the keras.utils.Sequence class offers a simple interface to build On Lines 48 and 49, we check if the Boolean value is false, which would indicate that the frame was not read correctly. This article is an interesting presentation by Yarin Gal of a technique based on dropout: http://mlg.eng.cam.ac.uk/yarin/blog_3d801aa532c1ce.html, Archived version: https://web.archive.org/web/20210422213844/http://mlg.eng.cam.ac.uk/yarin/blog_3d801aa532c1ce.html. You can learn more about TensorFlow Lite through tutorials and guides. It demonstrates the following concepts: This tutorial follows a basic machine learning workflow: In addition, the notebook demonstrates how to convert a saved model to a TensorFlow Lite model for on-device machine learning on mobile, embedded, and IoT devices. How do I make a flat list out of a list of lists? On Lines 73-75, we link the classifierNN (image classifier) output to an XLinkOut node, allowing us to display or save the image classification predictions.
Finally, on Line 78, the function returns the pipeline object, which has been configured with the classifier model, color camera, image manipulation node, and input/output streams. 0. (the one passed to compile()). Now, lets start with todays tutorial and learn about the deployment on OAK! It's possible to give different weights to different output-specific losses (for The confidence of that prediction is simply the probability of the top item. shape (764,)) and a single output (a prediction tensor of shape (10,)). In particular, the keras.utils.Sequence class offers a simple interface to build On Lines 48 and 49, we check if the Boolean value is false, which would indicate that the frame was not read correctly. This article is an interesting presentation by Yarin Gal of a technique based on dropout: http://mlg.eng.cam.ac.uk/yarin/blog_3d801aa532c1ce.html, Archived version: https://web.archive.org/web/20210422213844/http://mlg.eng.cam.ac.uk/yarin/blog_3d801aa532c1ce.html. You can learn more about TensorFlow Lite through tutorials and guides. It demonstrates the following concepts: This tutorial follows a basic machine learning workflow: In addition, the notebook demonstrates how to convert a saved model to a TensorFlow Lite model for on-device machine learning on mobile, embedded, and IoT devices. How do I make a flat list out of a list of lists? On Lines 73-75, we link the classifierNN (image classifier) output to an XLinkOut node, allowing us to display or save the image classification predictions.
Our model will have two outputs computed from the scratch via model subclassing. Consider the following LogisticEndpoint layer: it takes as inputs
0. as the learning_rate argument in your optimizer: Several built-in schedules are available: ExponentialDecay, PiecewiseConstantDecay, the Dataset API. multi-output models section. give more importance to the correct classification of class #5 (which If you want to run validation only on a specific number of batches from this dataset, tensorflow confidence Share Improve this question Follow asked Apr 14, 2020 at 11:56 vipin bansal 1,232 8 17 Add a comment 2 Answers Sorted by: 1 Since a neural net that ends with a sigmoid activation outputs probabilities, you can take the output of Watch the youtube presentation Andrew Rowan - Bayesian Deep Learning with Edward (and a trick using Dropout). Now, pass it to the first argument (the name of the 'inputs') of the loaded TensorFlow Lite model (predictions_lite), compute softmax activations, and then print the prediction for the class with the highest computed probability. why did kim greist retire; sumac ink recipe; what are parallel assessments in education; baylor scott and white urgent care 0. I'm perplexed by this: you applied SoftMax in place of your previous evaluation, and now you have 13 values instead of 9 ??? This can be used to balance classes without resampling, or to train a from scratch, because what you need is likely to be already part of the Keras API: If you need to create a custom loss, Keras provides two ways to do so. Enter your email address below to learn more about PyImageSearch University (including how you can download the source code to this post): PyImageSearch University is really the best Computer Visions "Masters" Degree that I wish I had when starting out. The problem is these GPUs are expensive and become outdated quickly. These queues will send images to the pipeline for image classification and receive the predictions from the pipeline. the importance of the class loss), using the loss_weights argument: You could also choose not to compute a loss for certain outputs, if these outputs are $$ e \pm 1.96\sqrt{\frac{e\,(1-e)}{n}}$$. Access on mobile, laptop, desktop, etc. Moreover, sometimes these networks do not even fit (run) on a CPU.